

Description
In many domains, such as biology, chemistry, medicine, and the humanities, visual exploratory data analysis is often not practicable due to size and unstructured nature of the data. Traditional machine learning (ML) requires large-scale labeled training data and a clear target definition, which is typically not available when exploring unknown data. For such large-scale, unstructured, open-ended, and domain-specific problems, we need an interactive approach combining the strengths of ML and human analytical skills into a unified process that helps users to "detect the expected and discover the unexpected".
In a project in collaboration with FH St.Pölten, we investigate how humans and machines can learn about and from the data in a joint fashion. The focus of TU Wien thereby lies on suitable visual interfaces that facilitate the joint human-machine data exploration process, particularly on two main aspects:
1) How users can effortlessly and effectively externalize what they already know or expect from the data and
2) how to represent the data to support the users' current understanding and challenge them to extend their knowledge at the same time.
All projects can also be performed as paid student assistant (studentische MA in Forschung und Verwaltung)!
If you are interested, please contact Manuela Waldner.
Projects
Within this project, the following student project and theses topics are currently available:
(BA/PR/DA, 1 person): Visual and (Inter)Active Learning - Design Space (and Study): Active learning is an established and successful strategy to effectively label large amounts of data, but also has been found to be annoying by users [Amershi et al., AI Magazine 2014]. At least for simple examples, selecting data points to label from a visualization can be similarly effective but more enjoyable [Bernard et al., TVCG 2017]. Combinations of these two approaches are possible (e.g., [Bernard et al., Visual Computer 2018]). In this work, the design space of visual interfaces combining active learning and visual interactive labeling should be explored to support labeling of large datasets with real-world complexity (i.e., "beyond MNIST"). For BA / PR, an interface with varying degree of system and user initiative should be designed and implemented within our existing software framework. For DA, the design space should be additionally validated through a user study based on the implementation.
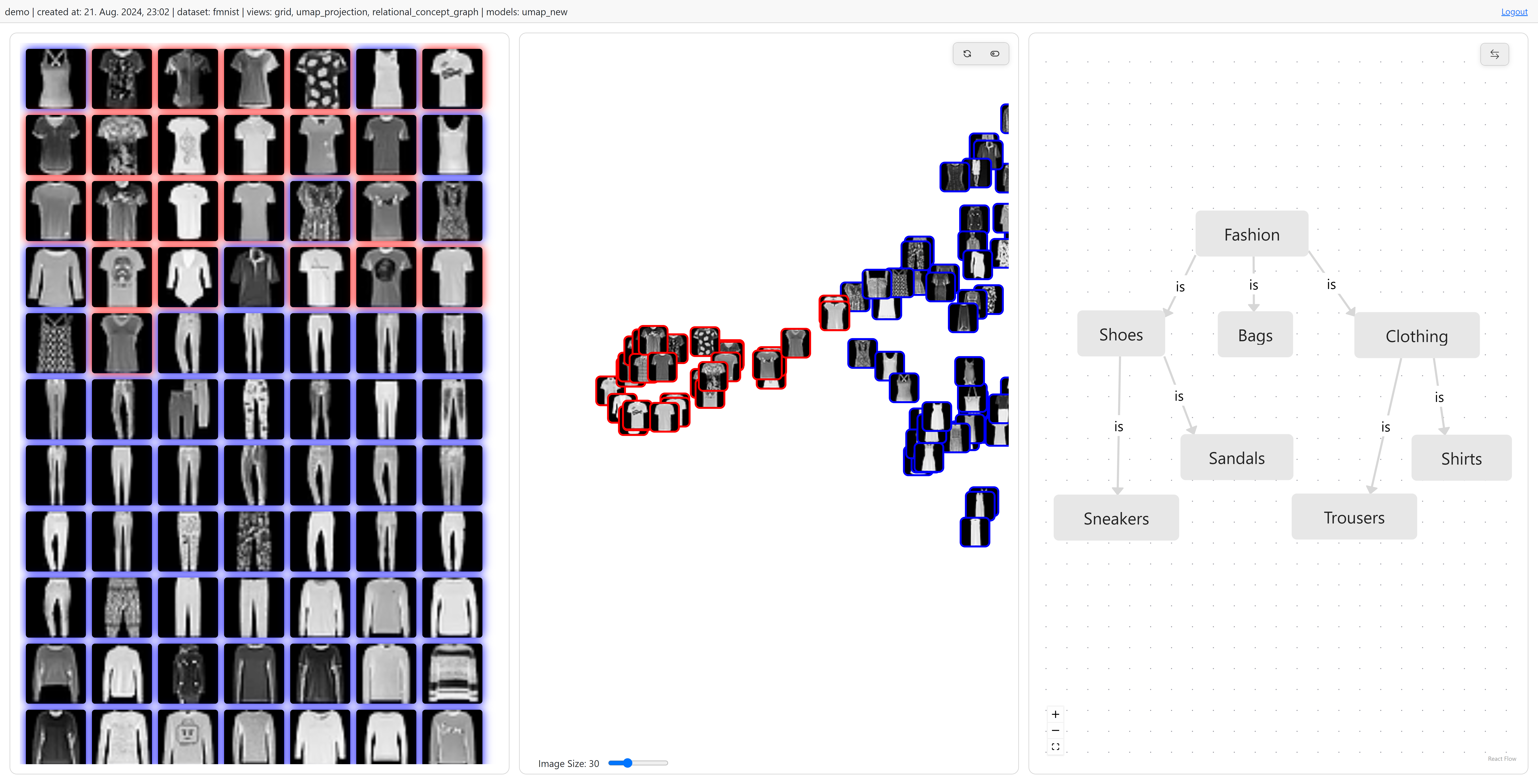
(PR/DA, 1 person): High-Dimensional Aggregates: Using dimensionality reduction techniques, we can visualize the similarity images, time series data, and other types of unstructured data, through a 2D projection. These projections can then be analyzed to assess the accuracy of models or to select items for labeling. When visualizing many data instances, aggregation strategies (e.g., clustering) are necessary to avoid visual clutter. Aggregates can be computed in the projection space or in a higher-dimensional feature space. There are also different methods to visualize aggregates - from simple color-coding of items belonging to the same aggregate to highly abstract representations, where aggregates are substituted by simple graphical elements. This work should explore the design space and integrate an aggregate visualization technique, where we can control the degree of visual abstraction and the space in which the aggregations are computed, into an existing software framework. For DA, the work shall rigorously validate the design space based on multiple characteristics, such as visual clutter and representativeness of the visualized aggregates. The work can build upon a previous student project on visualization of high-dimensional clusters [Wolf, student project TU Wien 2023].
(PR, 1 person): GPU-Accelerated Data Analysis / ML Backend: Our software framework consists of a Python backend, which is responsible for data analysis and machine learning, as well as a JavaScript / React / d3 frontend for data visualization and interaction. To make the backend more efficient, this project should extend our software framework with GPU-accelerated data analysis using, for instance, rapids.ai. In the course of the project, the costs and benefits of GPU accelerated data analysis should be systematically tested for different scenarios. One scenario would be to integrate interactive ProtoNetVis [Stoff, Master Thesis, TU Wien 2025], which is too slow for interactive data analysis when computed on the CPU.
(BA/PR/DA, 1 person): Interactive Sampling and Visualization: When visualizing large unstructured data, it is not possible to show all data items at all times. In this project, students should systematically investigate different sampling strategies depending on the user's current knowledge, extending upon prior experiments on knowledge-independent scatterplot sampling [Yuan et al., TVCG 2020]. This project will be co-supervised the computer graphics research unit and the machine learning research unit. Depending on the project type, the topic can be combined with the topic "GPU-accelerated backend" (see above).
(BA/PR/DA, 1 person): Zero-Shot Scatterplot Annotation: Dimensionality reduction techniques like UMAP are commonly used to visualize unstructured data sets, like image collections. To better grasp the content of a (cluttered) visualization, annotations can be added (see for instance, [Ren et al., TVCG 2017]). In this work, scatterplots should be automatically annotated using pre-trained zero-shot classification models to help users getting an overview of the visualized data. Depending on the project type, different models and preprocessing approaches should be systematically evaluated.
(BA/PR/DA, 1-2 persons): Zero-Shot Mapping of Free-Form Text Notes to Data: One effortless method to externalize knowledge is unstructured note-taking in text form. The open question is how accurately we can link free-form user notes to the data to be analyzed and how to integrate users' notes into an interactive data exploration interface. Depending on the project type, students implement an interface prototype and / or perform a controlled user study to compare free-form note taking with our structured knowledge externalization interface [Eschner et al., CGF 2025].
(BA/PR/DA, 1 person): Complex Interactive Annotation: Interactive data annotation by humans is essential for a machine backend to incrementally learn the underlying semantics of the data. Existing systems typically constrain the user in the way how they can annotate the data - for instance into a set of flat labels [see Dudley and Kristensson, ACM TiiS 2018 for a survey]. However, users may wish to describe more complex semantics, such as hierarchical or multi-dimensional relations. In this work, the student shall develop an effective model and interface for letting users express such complex semantics and match them with the data items.
Requirements
- Strong interest in visualization, user interfaces, machine learning, and human-computer interaction
- Very good programming skills
- Experience with web technologies (JavaScript, d3, ...) as well as Python advantageous
- Experience with ML libraries also advantageous
Environment
The projects shall be developed within an existing framework based on a React and TypeScript frontend and a Python backend. The code can be found in GitLab. More information about the project can be found here.